materials
Ajax
- Ajax
Introducción
AJAX es el acrónimo de Asynchronous Javascript And XML (Javascript asíncrono y XML) y es lo que usamos para hacer peticiones asíncronas al servidor desde Javascript. Cuando hacemos una petición al servidor no nos responde inmediatamente (la petición tiene que llegar al servidor, procesarse allí y enviarse la respuesta que llegará al cliente).
Lo que significa asíncrono es que la página no permanecerá bloqueada esperando esa respuesta sino que continuará ejecutando su código e interactuando con el usuario, y en el momento en que llegue la respuesta del servidor se ejecutará la función que indicamos al hacer la llamada Ajax. Respecto a XML, es el formato en que se intercambia la información entre el servidor y el cliente, aunque actualmente el formato más usado es JSON que es más simple y legible.
Básicamente Ajax nos permite poder mostrar nuevos datos enviados por el servidor sin tener que recargar la página, que continuará disponible mientras se reciben y procesan los datos enviados por el servidor en segundo plano.

Sin Ajax cada vez que necesitamos nuevos datos del servidor la página deja de estar disponible para el usuario hasta que se recarga con lo que envía el servidor. Con Ajax la página está siempre disponible para el usuario y simplemente se modifica (cambiando el DOM) cuando llegan los datos del servidor:
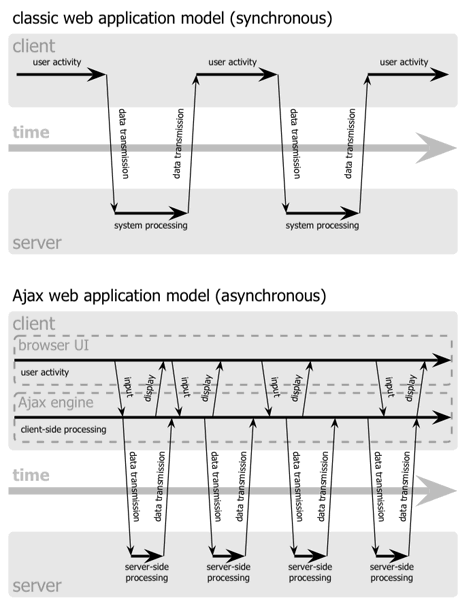 Fuente Uniwebsidad
Fuente Uniwebsidad
Métodos HTTP
Las peticiones Ajax usan el protocolo HTTP (el mismo que utiliza el navegador para cargar una página). Este protocolo envía al servidor unas cabeceras HTTP (con información como el userAgent del navegador, el idioma, etc), el tipo de petición y, opcionalmente, datos o parámetros (por ejemplo en la petición que procesa un formulario se envían los datos del mismo).
Hay diferentes tipos de petición que podemos hacer:
- GET: suele usarse para obtener datos sin modificar nada (equivale a un SELECT en SQL). Si enviamos datos (ej. la ID del registro a obtener) suelen ir en la url de la petición (formato URIEncoded). Ej.: locahost/users/3, https://jsonplaceholder.typicode.com/users o www.google.es?search=js
- POST: suele usarse para añadir un dato en el servidor (equivalente a un INSERT). Los datos enviados van en el cuerpo de la petición HTTP (igual que sucede al enviar desde el navegador un formulario por POST)
- PUT: es similar al POST pero suele usarse para actualizar datos del servidor (como un UPDATE de SQL). Los datos se envían en el cuerpo de la petición (como en el POST) y la información para identificar el objeto a modificar en la url (como en el GET). El servidor hará un UPDATE sustituyendo el objeto actual por el que se le pasa como parámetro
- PATCH: es similar al PUT pero la diferencia es que en el PUT hay que pasar todos los campos del objeto a modificar (los campos no pasados se eliminan del objeto) mientras que en el PATCH sólo se pasan los campos que se quieren cambiar y en resto permanecen como están
- DELETE: se usa para eliminar un dato del servidor (como un DELETE de SQL). La información para identificar el objeto a eliminar se envía en la url (como en el GET)
- existen otros tipos que no veremos aquí (como HEAD, PATCH, etc)
El servidor acepta la petición, la procesa y le envía una respuesta al cliente con el recurso solicitado y además unas cabeceras de respuesta (con el tipo de contenido enviado, el idioma, etc) y el código de estado. Los códigos de estado más comunes son:
- 2xx: son peticiones procesadas correctamente. Las más usuales son 200 (ok) o 201 (created, como respuesta a una petición POST satisfactoria)
- 3xx: son códigos de redirección que indican que la petición se redirecciona a otro recurso del servidor, como 301 (el recurso se ha movido permanentemente a otra URL) o 304 (el recurso no ha cambiado desde la última petición por lo que se puede recuperar desde la caché)
- 4xx: indican un error por parte del cliente, como 404 (Not found, no existe el recurso solicitado) o 401 (Not authorized, el cliente no está autorizado a acceder al recurso solicitado)
- 5xx: indican un error por parte del servidor, como 500 (error interno del servidor) o 504 (timeout, el servidor no responde).
En cuanto a la información enviada por el servidor al cliente normalmente serán datos en formato JSON o XML (cada vez menos usado) que el cliente procesará y mostrará en la página al usuario. También podría ser HTML, texto plano, …
El formato JSON es una forma de convertir un objeto Javascript en una cadena de texto para poderla enviar, por ejemplo el objeto
let alumno = {
id: 5,
nombre: Marta,
apellidos: Pérez Rodríguez
}
se transformaría en la cadena de texto
{ "id": 5, "nombre": "Marta", "apellidos": "Pérez Rodríguez" }
y el array
let alumnos = [
{
id: 5,
nombre: "Marta",
apellidos: "Pérez Rodríguez"
},
{
id: 7,
nombre: "Joan",
apellidos: "Reig Peris"
},
]
en la cadena:
[{ "id": 5, "nombre": Marta, "apellidos": Pérez Rodríguez }, { "id": 7, "nombre": "Joan", "apellidos": "Reig Peris" }]
Para convertir objetos en cadenas de texto JSON y viceversa Javascript proporciona 2 funciones:
- JSON.stringify(objeto): recibe un objeto JS y devuelve la cadena de texto correspondiente. Ej.:
const cadenaAlumnos = JSON.stringify(alumnos) - JSON.parse(cadena): realiza el proceso inverso, convirtiendo una cadena de texto en un objeto. Ej.:
const alumnos = JSON.parse(cadenaAlumnos)
EJERCICIO: Vamos a realizar diferentes peticions HTTP a la API https://jsonplaceholder.typicode.com, en concreto trabajaremos contra la tabla todos con tareas para hacer. Las peticiones GET podríamos hacerlas directamente desde el navegador pero para el resto debemos instalar alguna de las extensiones de cliente REST en nuestro navegador. Por tanto instalaremos dicha extensión (por ejemplo Advanced Rest Client para Chrome o Rested para Firefox y haremos todas las peticiones desde allí (incluyendo los GET) lo que nos permitirá ver los códigos de estado devueltos, las cabeceras, etc.
Lo que queremos hacer en este ejercicio es:
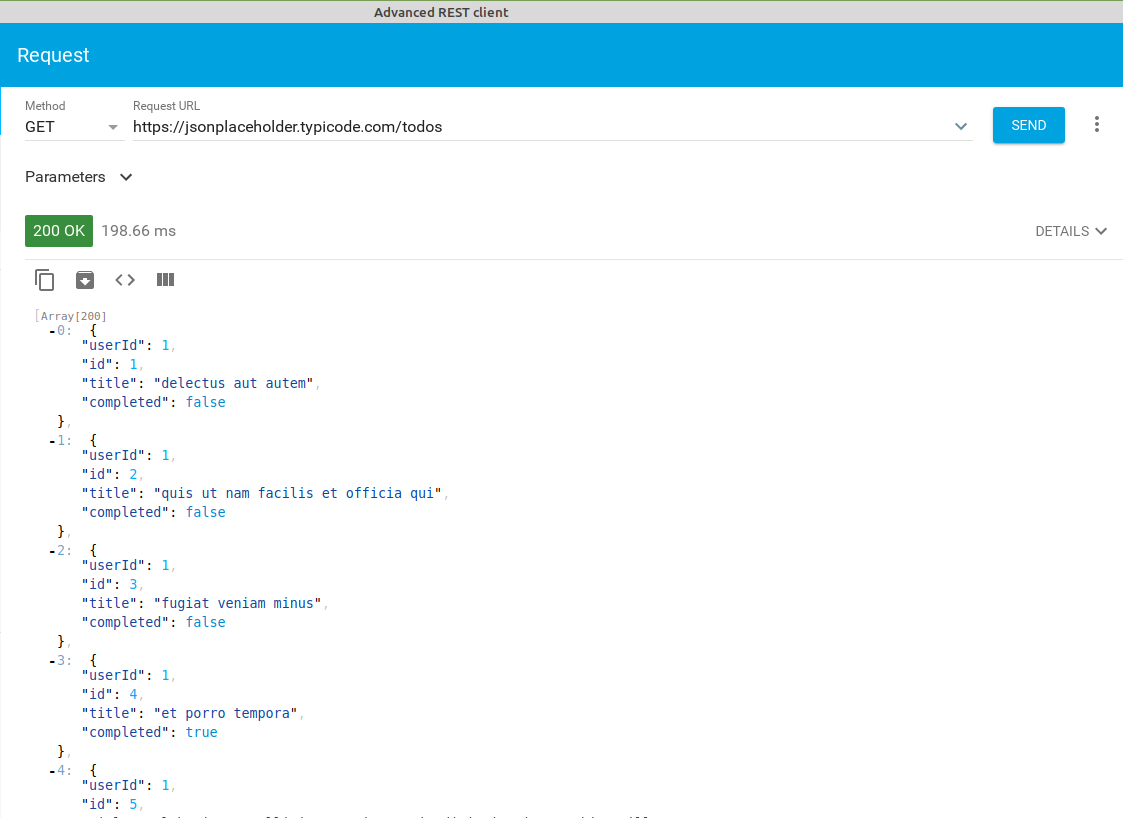
obtener todas las tareas (devuelve un array con todas las tareas y el código devuelto será 200 - Ok)
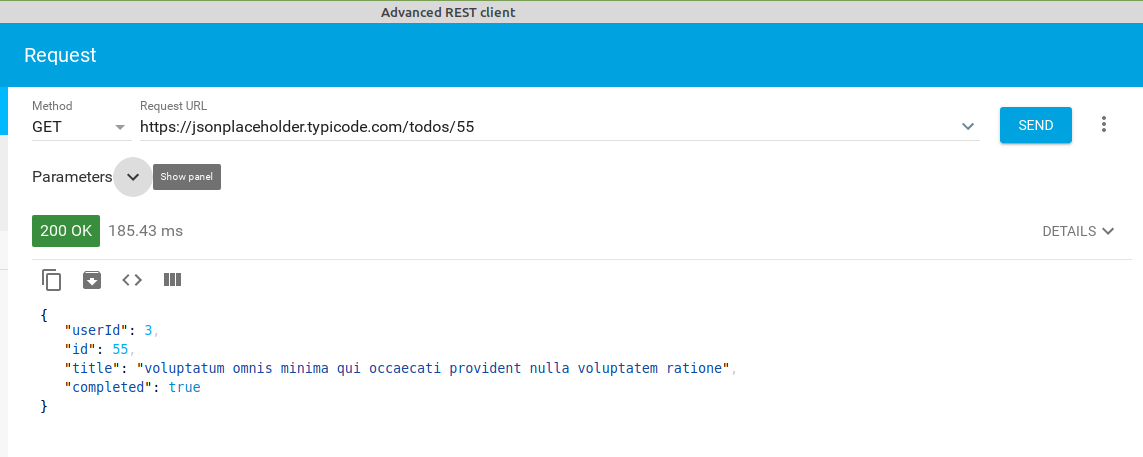
obtener la tarea con id 55 (devuelve el objeto de la tarea 55 y el código devuelto será 200 - Ok)
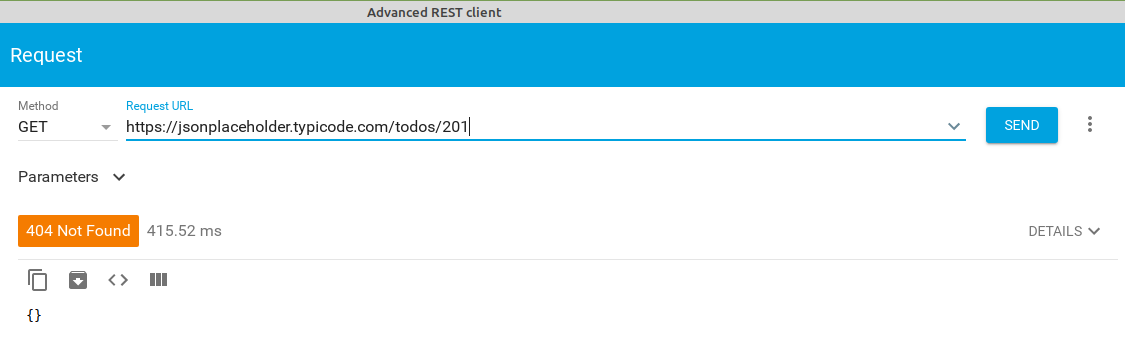
obtener la tarea con id 201 (como no existe devolverá un objeto vacío y como código de error 404 - Not found)
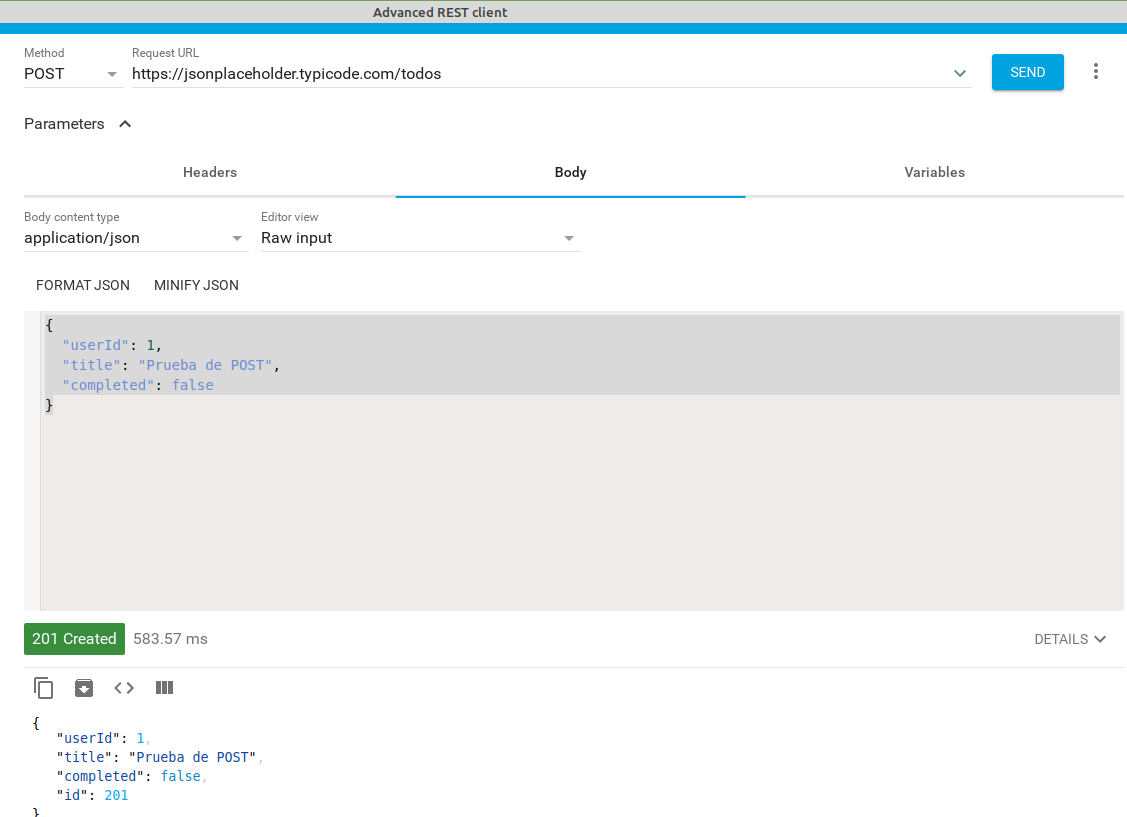
- crear una nueva tarea. En el cuerpo de la petición le pasaremos sus datos: userID: 1, title: Prueba de POST y completed: false. No se le pasa la id (de eso se encarga la BBDD). La respuesta debe ser un código 201 (created) y el nuevo registro creado con todos sus datos incluyendo la id. Como es una API de prueba en realidad no lo está añadiendo a la BBDD por lo que si luego hacemos una petición buscando esa id nos dirá que no existe.
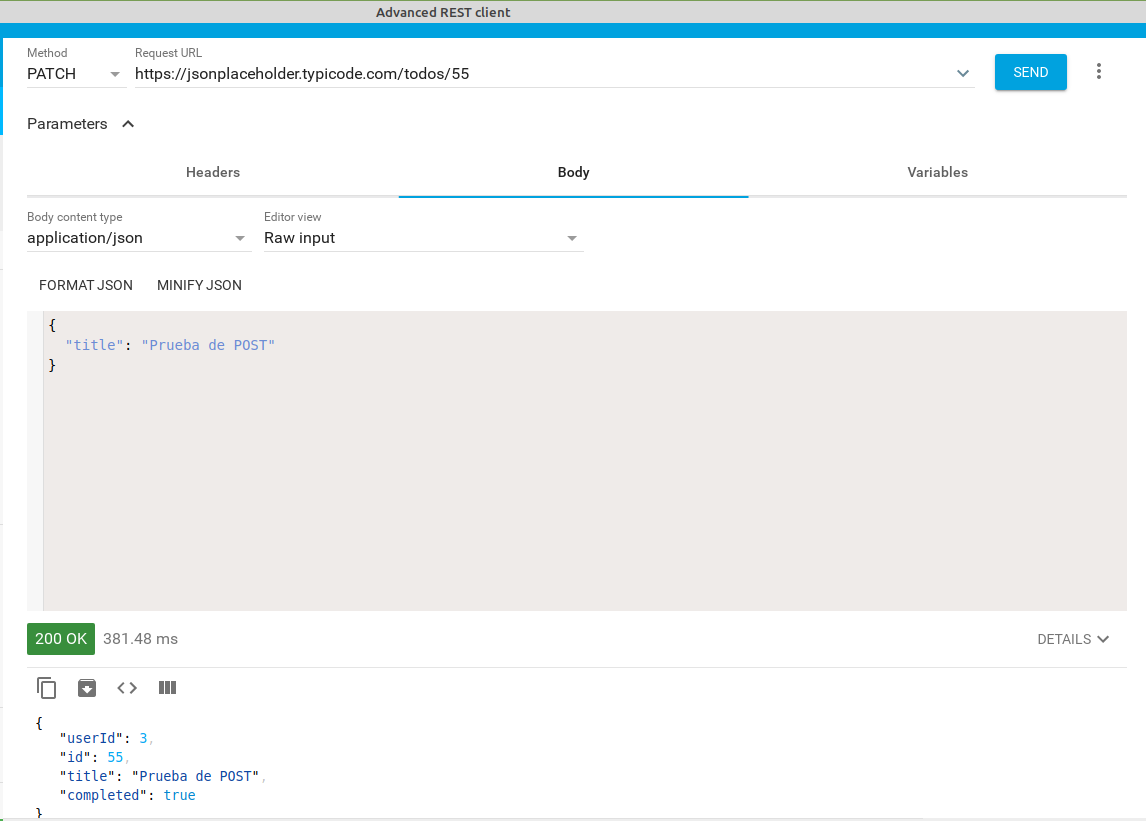
- modificar con un PATCH la tarea con id 55 para que su title sea ‘Prueba de POST’. Devolverá el nuevo registro con un código 200. Como veis al hacer un PATCH los campos que no se pasan se mantienen como estaban
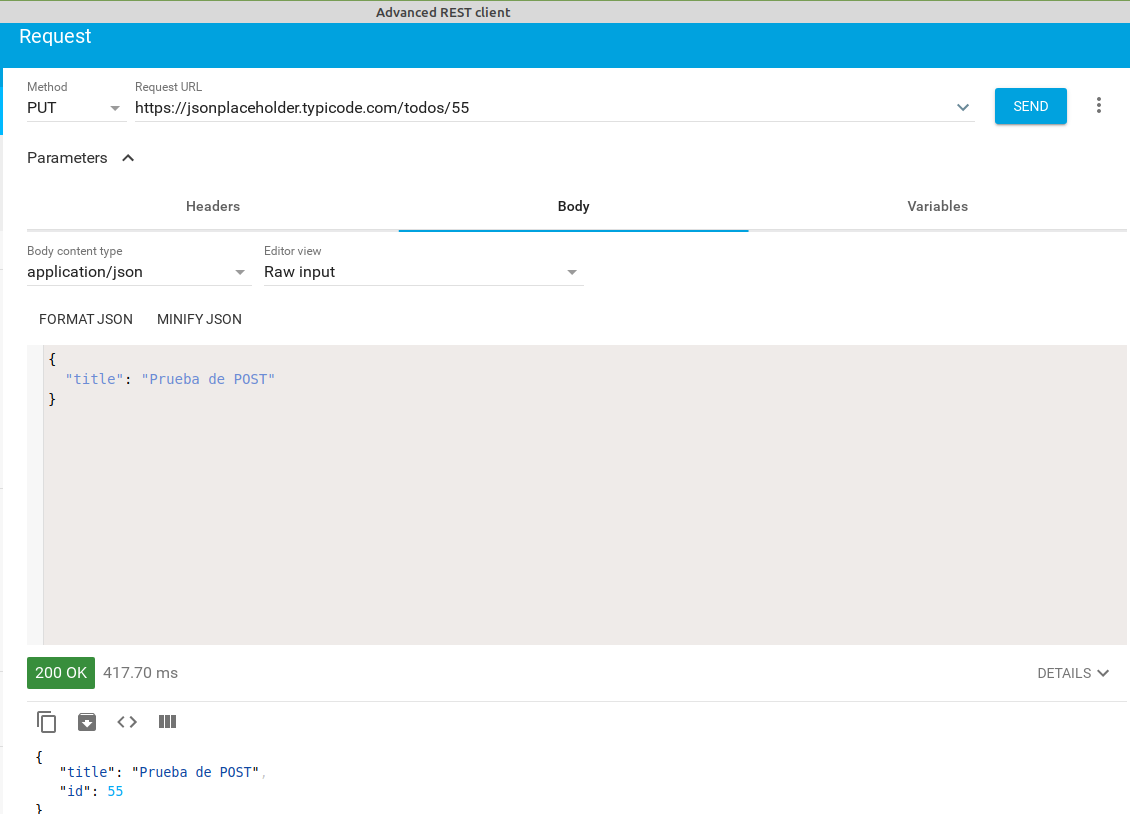
- modificar con un PUT la tarea con id 55 para que su title sea ‘Prueba de POST’. Devolverá el nuevo registro con un código 200. Como veis en esta API los campos que no se pasan se eliminan; en otras los campos no pasados se mantienen como estaban
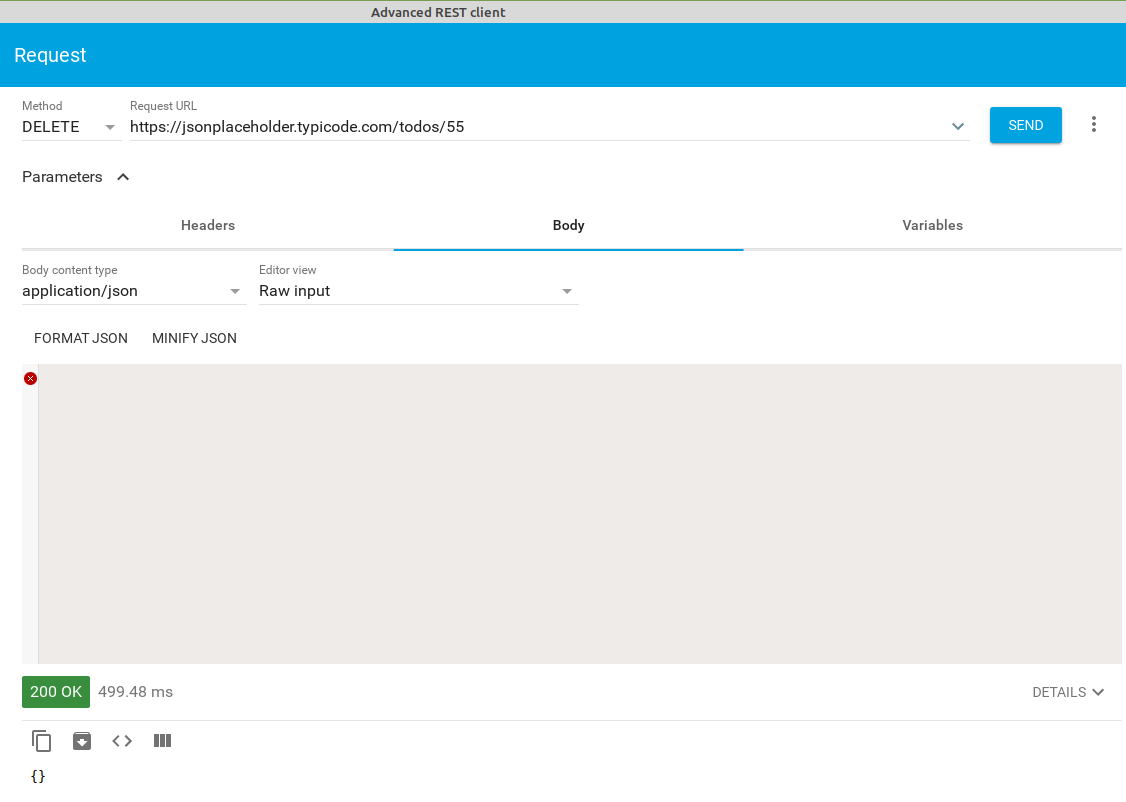
- eliminar la tarea con id 55. Como veis esta API devuelve un objeto vacío al eliminar; otras devuelven el objeto eliminado
Json Server
Las peticiones Ajax se hacen a un servidor que proporcione una API. Como ahora no tenemos ninguno podemos utilizar Json Server que es un servidor API-REST que funciona bajo Node.js (que ya tenemos instalado para usar NPM) y que utiliza un fichero JSON como contenedor de los datos en lugar de una base de datos.
Para instalarlo en nuestra máquina (lo instalaremos global para poderlo usar en todas nuestras prácticas) ejecutamos:
npm install -g json-server
Para que sirva un fichero datos.json:
json-server datos.json
Le podemos poner la opción --watch ( o -w) para que actualice los datos si se modifica el fichero .json externamente (si lo editamos).
El fichero datos.json será un fichero que contenga un objeto JSON con una propiedad para cada “tabla” de nuestra BBDD. Por ejemplo, si queremos simular una BBDD con las tablas users y posts vacías el contenido del fichero será:
{
"users": [],
"posts": []
}
La API escucha en el puerto 3000 y servirá los diferentes objetos definidos en el fichero .json. Por ejemplo:
- http://localhost:3000/users: devuelve un array con todos los elementos de la tabla users del fichero .json
- http://localhost:3000/users/5: devuelve un objeto con el elemento de la tabla users cuya propiedad id valga 5
También pueden hacerse peticiones más complejas como:
- http://localhost:3000/users?rol=3: devuelve un array con todos los elementos de users cuya propiedad rol valga 3
Para más información: https://github.com/typicode/json-server.
Si queremos acceder a la API desde otro equipo (no desde localhost) tenemos que indicar la IP de la máquina que ejecuta json-server y que se usará para acceder, por ejemplo si vamos a ejecutarlo en la máquina 192.168.0.10 pondremos:
json-server --host 192.168.0.10 datos.json
Y la ruta para acceder a la API será http://192.168.0.10:3000.
EJERCICIO: instalar json-server en tu máquina. Ejecútalo indicando un nombre de fichero que no existe: como verás crea un fichero json de prueba con 3 tablas: posts, comments y profiles. Ábrelo en tu navegador para ver los datos
REST client
Para probar las peticiones GET podemos poner la URL en la barra de direcciones del navegador pero para probar el resto de peticiones debemos instalar en nuestro navegador una extensión que nos permita realizar las peticiones indicando el método a usar, las cabeceras a enviar y los datos que enviaremos a servidor, además de la URL.
Existen multitud de aplicaciones para realizar peticiones HTTP, como Advanced REST client. Cada navegador tiene sus propias extensiones para hacer esto, como Advanced Rest Client para Chrome o RestClient para Firefox.
El objeto XMLHttpRequest
Hasta ahora hemos hecho un repaso a lo que es el protocolo HTTP. Ahora que lo tenemos claro y hemos instalado un servidor que nos proporciona una API (json-server) vamos a realizar peticiones HTTP en nuestro código javascript usando Ajax.
Para hacer una petición debemos crear una instancia del objeto XMLHttpRequest que es el que controlará todo el proceso. Los pasos a seguir son:
- Creamos la instancia del objeto:
const peticion=new XMLHttpRequest() - Para establecer la comunicación con el servidor ejecutamos el método .open() al que se le pasa como parámetro el tipo de petición (GET, POST, …) y la URL del servidor:
peticion.open('GET', 'https://jsonplaceholder.typicode.com/users') - OPCIONAL: Si queremos añadir cabeceras a la petición HTTP llamaremos al método .setRequestHeader(). Por ejemplo si enviamos datos con POST hay que añadir la cabecera Content-type que le indica al servidor en qué formato van los datos:
peticion.setRequestHeader('Content-type', 'application/x-www-form-urlencoded) - Enviamos la petición al servidor con el método .send(). A este método se le pasa como parámetro los datos a enviar al servidor en el cuerpo de la petición (si es un POST, PUT o PATCH le pasaremos una cadena de texto con los datos a enviar:
peticion.send('dato1='+encodeURIComponent(dato1)+'&dato2='+encodeURIComponent(dato2))). Si es una petición GET o DELETE no le pasaremos datos (peticion.send()) - Ponemos un escuchador al objeto peticion para saber cuándo está disponible la respuesta del servidor
Eventos de XMLHttpRequest
Tenemos diferentes eventos que el servidor envía para informarnos del estado de nuestra petición y que nosotros podemos capturar. El evento readystatechange se produce cada vez que el servidor cambia el estado de la petición. Cuando hay un cambio en el estado cambia el valor de la propiedad readyState de la petición. Sus valores posibles son:
- 0: petición no iniciada (se ha creado el objeto XMLHttpRequest)
- 1: establecida conexión con el servidor (se ha hecho el open)
- 2: petición recibida por el servidor (se ha hecho el send)
- 3: se está procesando la petición
- 4: petición finalizada y respuesta lista (este es el evento que nos interesa porque ahora tenemos la respuesta disponible) A nosotros sólo nos interesa cuando su valor sea 4 que significa que ya están los datos. En ese momento la propiedad status contiene el estado de la petición HTTP (200: Ok, 404: Not found, 500: Server error, …) que ha devuelto el servidor. Cuando readyState vale 4 y status vale 200 tenemos los datos en la propiedad responseText (o responseXML si el servidor los envía en formato XML).
El siguiente ejemplo nos enseña cómo se producen los distintos eventos en una petición asíncrona:
const peticion = new XMLHttpRequest();
console.log("Estado inicial de la petición: " + peticion.readyState);
peticion.open('GET', 'https://jsonplaceholder.typicode.com/users');
console.log("Estado de la petición tras el 'open': " + peticion.readyState);
peticion.send();
console.log("Petición hecha");
peticion.addEventListener('readystatechange', function() {
console.log("Estado de la petición: " + peticion.readyState);
if (peticion.readyState === 4) {
if (peticion.status === 200) {
console.log("Datos recibidos:");
let usuarios = JSON.parse(peticion.responseText); // Convertirmos los datos JSON a un objeto
console.log(usuarios);
} else {
console.log("Error " + peticion.status + " (" + peticion.statusText + ") en la petición");
}
}
})
console.log("Petición acabada");
El resultado de ejecutar ese código es el siguiente:

Fijaos cuándo cambia de estado (readyState) la petición:
- vale 0 al crear el objeto XMLHttpRequest
- vale 1 cuando abrimos la conexión con el servidor
- luego se envía al servidor y es éste el que va informando al cliente de cuándo cambia su estado
MUY IMPORTANTE: notad que la última línea (‘Petición acabada’) se ejecuta antes que las de ‘Estado de la petición’. Recordad que es una petición asíncrona y la ejecución del programa continúa sin esperar a que responda el servidor.
Como normalmente no nos interesa cada cambio en el estado de la petición sino que sólo queremos saber cuándo ha terminado de procesarse tenemos otros eventos que nos pueden ser de utilidad:
- load: se produce cuando se recibe la respuesta del servidor. Equivale a readyState===4. En status tendremos el estado de la respuesta
- error: se produce si sucede algún error al procesar la petición (de red, de servidor, …)
- timeout: si ha transcurrido el tiempo indicado y no se ha recibido respuesta del servidor. Podemos cambiar el tiempo por defecto modificando la propiedad timeout antes de enviar la petición
- abort: si se cancela la petición (se hace llamando al método .abort() de la petición)
- loadend: se produce siempre que termina la petición, independientemente de si se recibe respuesta o sucede algún error (incluyendo un timeout o un abort)
Este es un ejemplo de código que sí podríamos usar para este tipo de peticiones:
const peticion=new XMLHttpRequest();
peticion.open('GET', 'https://jsonplaceholder.typicode.com/users');
peticion.send();
peticion.addEventListener('load', function() {
if (peticion.status===200) {
let usuarios=JSON.parse(peticion.responseText);
// procesamos los datos que tenemos en usuarios
} else {
muestraError(peticion);
}
})
peticion.addEventListener('error', muestraError);
peticion.addEventListener('abort', muestraError);
peticion.addEventListener('timeout', muestraError);
function muestraError(peticion) {
if (peticion.status) {
console.log("Error "+peticion.status+" ("+peticion.statusText+") en la petición");
} else {
console.log("Ocurrió un error o se abortó la conexión");
}
}
Recuerda que tratamos con peticiones asíncronas por lo que tras la línea
peticion.addEventListener('load', function() {
no se ejecuta la línea siguiente
if (peticion.status===200) {
sino la de
peticion.addEventListener('error', muestraError);
Una petición asíncrona es como pedir una pizza: tras llamar por teléfono lo siguiente no es ir a la puerta a recogerla sino que seguimos haciendo cosas por casa y cuando suena el timbre de casa entonces vamos a la puerta a por ella.
Ejemplos de envío de datos
Podemos enviar datos al servidor en el cuerpo de la petición http. Siempre deberemos indicar en una cabecera de la petición en qué formato enviamos los datos y en función de dicho formato se hace la petición de diferente manera.
Vamos a ver algunos ejemplos de envío de datos al servidor con POST. Supondremos que tenemos una página con un formulario para dar de alta nuevos productos:
<form id="addProduct">
<label for="name">Nombre: </label><input type="text" name="name" id="name" required><br>
<label for="descrip">Descripción: </label><input type="text" name="descrip" id="descrip" required><br>
<button type="submit">Añadir</button>
</form>
Enviar datos al servidor en formato JSON
document.getElementById('addProduct').addEEventListener('submit', (event) => {
...
const newProduct={
name: document.getElementById("name").value,
descrip: document.getElementById("descrip").value,
}
const peticion=new XMLHttpRequest();
peticion.open('POST', 'https://localhost/products');
peticion.setRequestHeader('Content-type', 'application/json'); // Siempre tiene que estar esta línea si se envían datos
peticion.send(JSON.stringify(newProduct)); // Hay que convertir el objeto a una cadena de texto JSON para enviarlo
peticion.addEventListener('load', function() {
// procesamos los datos
...
})
})
Para enviar el objeto hay que convertirlo a una cadena JSON con la función JSON.stringify(). Siempre que enviamos datos al servidor debemos decirle el formato que tienen en la cabecera de Content-type:
peticion.setRequestHeader('Content-type', 'application/json');
Enviar datos al servidor en formato URIEncoded
document.getElementById('addProduct').addEEventListener('submit', (event) => {
...
const name=document.getElementById("name").value;
const descrip=document.getElementById("descrip").value;
const peticion=new XMLHttpRequest();
peticion.open('GET', 'https://localhost/products');
peticion.setRequestHeader('Content-type', 'application/x-www-form-urlencoded');
peticion.send('name='+encodeURIComponent(name)+'&descrip='+encodeURIComponent(descrip));
peticion.addEventListener('load', function() {
...
})
})
En este caso los datos se envían como hace el navegador por defecto en un formulario. Recordad siempre codificar lo que introduce el usuario para evitar problemas con caracteres no estándar y ataques SQL Injection u otros.
Enviar ficheros al servidor con FormData
FormData es una interfaz de XMLHttpRequest que permite construir fácilmente pares de clave=valor para enviar los datos de un formulario. Se envían en el mismo formato en que se enviarían directamente desde un formulario (“multipart/form-data”) por lo que no hay que poner encabezado de ‘Content-type’.
De esta manera podemos enviar ficheros al servidor, no sólo valores de texto.
Vamos a añadir al formulario un campo donde el usuario pueda subir la foto del producto:
<form id="addProduct">
<label for="name">Nombre: </label><input type="text" name="name" id="name" required><br>
<label for="descrip">Descripción: </label><input type="text" name="descrip" id="descrip" required><br>
<label for="photo">Fotografía: </label><input type="file" name="photo" id="photo" required><br>
<button type="submit">Añadir</button>
</form>
Podemos enviar al servidor todo el contenido del formulario:
document.getElementById('addProduct').addEventListener('submit', (event) => {
...
const peticion=new XMLHttpRequest();
const datosForm = new FormData(document.getElementById('addProduct'));
// Automáticamente ha añadido todos los inputs, incluyendo tipo 'file', blob, ...
// Si quisiéramos añadir algún dato más haríamos:
formData.append('otrodato', 12345);
// Y lo enviamos
peticion.open('POST', 'https://localhost/products');
peticion.send(datosForm);
peticion.addEventListener('load', function() {
...
})
})
También podemos enviar sólo los campos que queramos:
document.getElementById('addProduct').addEEventListener('submit', (event) => {
...
const formData=new FormData(); // creamos un formData vacío
formData.append('name', document.getElementById('name').value);
formData.append('descrip', document.getElementById('descrip').value);
formData.append('photo', document.getElementById('photo').files[0]);
const peticion=new XMLHttpRequest();
peticion.open('POST', 'https://localhost/products');
peticion.send(formData);
peticion.addEventListener('load', function() {
...
})
})
Podéis ver más información de cómo usar formData en MDN web docs.
Callbakcs, Promesas y Async/Await
Para ver un ejemplo real de cómo e haría una llamada a Ajax vamos a hacer una página que muestre en una tabla los posts del usuario indicado en un input. En resumen lo que hacemos es:
- El usuario de nuestra aplicación introduce el código del usuario del que queremos ver sus posts
- Tenemos un escuchador para que al introducir un código de un usuario llamamos a una función getPosts() que:
- Se encarga de hacer la petición Ajax al servidor
- Si se produce un error se encarga de informar al usuario de nuestra aplicación
- Cuando se reciben los datos del servidor deben pintarse en la tabla
Si Ajax fuera síncrono…
Si Ajax no fuera una petición asíncrona el código de todo esto será algo como el siguiente (ATENCIÓN, este código NO FUNCIONA):
Pero esto no funciona porque el valor de posts siempre es undefined. Esto es porque cuando se llama a getPosts esta función no devuelve nada (por eso posts es undefined) sino que devuelve los datos tiempo después, cuando el servidor contesta, pero entonces ya no hay nadie escuchando.
Solución mala
La solución es que todo el código, no sólo de la petición Ajax sino también el de qué hacer con los datos cuando llegan, se encuentre en la función que pide los datos al servidor:
Este código sí que funcionaría pero tiene una pega: tenemos que tratar los datos (en este caso pintarlos en la tabla) en la función que gestiona la petición porque es la que sabe cuándo están disponibles esos datos. Y sabemos que una función no debería tener 2 responsabilidades diferentes (obtener los datos del servidor y renderizarlos en la página).
Algo mejor: Funciones callback
Esto se podría mejorar usando una función callback. La idea es que creamos una función que procese los datos (renderPosts) y se la pasamos a getPosts para que la llame cuando tenga los datos:
Hemos creado una función que se ocupa de renderizar los datos y se la pasamos a la función que gestiona la petición para que la llame cuando los datos están disponibles. Utilizando la función callback hemos conseguido que getPosts() se encargue sólo de obtener los datos y cuando los tenga los pasa a la encargada de pintarlos en la tabla.
Solución buena: Promesas
Sin embargo hay una forma más limpia de resolver una función asíncrona y que el código se parezca al primero que hicimos que no funcionaba, donde la función getPosts() sólo debía ocuparse de obtener los datos y devolverlos a quien se los pidió. Ese código era:
...
let idUser = document.getElementById('id-usuario').value;
if (isNaN(idUser) || idUser == '') {
alert('Debes introducir un número');
} else {
const posts = getPosts(idUser);
// y aquí usamos los datos recibidos, en este caso para pintar los posts
}
...
Como dijimos esto NO funciona, a menos que convirtamos a getPosts() en una promesa. Cuando se realiza una llamada a una promesa quien la llama puede usar unos métodos (.then() y .catch()) que NO SE EJECUTARÁN hasta que la promesa se haya resuelto (es decir, hasta que el servidor haya contestado):
.then(_function(datos) { ... }_): se ejecuta cuando la promesa se haya resuelto satisfactoriamente. Su parámetro es una función que recibe como parámetro los datos que haya devuelto la promesa (que serán los datos pedidos al servidor)- .catch(function(datos) { … }): se ejecuta cuando se haya rechazado la promesa (si ha fallado, normalmente porque se ha recibido una respuesta errónea del servidor). Esta función recibe como parámetro la información pasada por la promesa al ser rechazada (que será información sobre el error producido).
De esta manera nuestro código quedaría:
...
let idUser = document.getElementById('id-usuario').value
if (isNaN(idUser) || idUser == '') {
alert('Debes introducir un número')
} else {
getPosts(idUser)
.then((posts) => { // aquí ya tenemos los datos en 'posts'
tbody.innerHTML = ''
posts.forEach((post) => {
const newPost = document.createElement('tr')
newPost.innerHTML = `
<td>${post.userId}</td>
<td>${post.id}</td>
<td>${post.title}</td>
<td>${post.body}</td>`
tbody.appendChild(newPost)
})
document.getElementById('num-posts').textContent = posts.length
})
// en el .catch() está el tratamiento de errores
.catch((error) => console.error(error))
}
Para convertir a getPosts() en una promesa sólo tenemos que “envolverla” en la instrucción
return new Promise((resolve, reject) => {
// Aquí el contenido de GetPosts()
})
Esto hace que devuelva un objeto de tipo Promise (return new Promise()) cuyo parámetro es una función que recibe 2 parámetros:
- resolve: función callback a la que se llamará cuando se resuelva la promesa satisfactoriamente
- reject: función callback a la que se llamará si se resuelve la promesa con errores
El funcionamiento es:
- cuando la promesa se resuelva satisfactoriamente getPosts llama a la función
resolve()y le pasa los datos recibidos por el servidor. Esto hace que se ejecute el método then de la llamada a la promesa que recibirá como parámetro esos datos - si se produce algún error se rechaza la promesa llamando a la función
reject()y pasando como parámetro la información del fallo producido y esto hará que se ejecute el .catch en la función que llamó a la promesa
Por tanto nuestra función getPosts ahora quedará así:
function getPosts(idUser) {
return new Promise((resolve, reject) => {
const peticion = new XMLHttpRequest();
peticion.open('GET', SERVER + '/posts?userId=' + idUser);
peticion.send();
peticion.addEventListener('load', () => {
if (peticion.status === 200) {
resolve(JSON.parse(peticion.responseText));
} else {
reject("Error " + peticion.status + " (" + peticion.statusText + ") en la petición");
}
})
peticion.addEventListener('error', () => reject('Error en la petición HTTP'));
})
}
Fijaos que el único cambio es la primera línea donde convertimos nuestra función en una promesa, y que luego para “devolver” los datos en lugar de hacer un return, que ya hemos visto que no funciona, se hace un resolve si todo ha ido bien o un reject si ha fallado.
Desde donde llamamos a la promesa nos suscribimos a ella usando los métodos .then() y .catch() que hemos visto anteriormente.
Básicamente lo que nos van a proporcionar las promesas es un código más claro y mantenible ya que el código a ejecutar cuando se obtengan los datos asíncronamente estará donde se piden esos datos y no en una función escuchadora o en una función callback.
Utilizando promesas vamos a conseguir que la función que pide los datos sea quien los obtiene y los trate o quien informa si hay un error.
El código del ejemplo de los posts usando promesas sería el siguiente:
NOTA: Fijaos que los errores del servidor SIEMPRE llegan a la consola. En el ejemplo anterior me aparecerán 2 veces: la primera que es el error original y la segunda donde lo pinto yo con el console.error.
Podéis consultar aprender más en MDN web docs.
La mejor solución: usar Async/Await
Las promesas son una mejora respecto a los callbacks pero aún así el código puede ser difícil de leer y mantener. Para solucionar esto se introdujeron en ES2017 las palabras reservadas async y await que permiten escribir código asíncrono de una manera más clara y sencilla.
La palabra reservada async se pone delante de una función e indica que esa función va a devolver una promesa. La palabra reservada await se pone delante de una llamada a una promesa y le indica a Javascript que espere a que esa promesa se resuelva antes de continuar con la ejecución del código.
Usando esto sí funcionaría el primer ejemplo que hicimos:
let idUser = document.getElementById('id-usuario').value;
if (isNaN(idUser) || idUser == '') {
alert('Debes introducir un número');
} else {
const posts = await getPosts(idUser);
// y aquí SÍ recibimos los datos porque ponemos AWAIT, en este caso para pintar los posts
}
Y la función getPosts() quedaría igual que la que hicimos con promesas.
Aquí el tratamiento de errores se hace con un try/catch:
try {
const posts = await getPosts(idUser);
} catch (error) {
console.error(error);
}
Usando async/await nuestro código se asemeja a un código síncrono ya que no continuan ejecutándose las instrucciones que hay después de un await hasta que esa petición se ha resuelto. Podemos anteponer un await a cualquier llamada a una función asíncrona, como una promesa, un setTimeout, …
Cualquier función que realice un await pasa a ser asíncrona ya que no se ejecuta al instante toda ella sino que se espera un tiempo. Para indicarlo debemos anteponer la palabra async a su declaración function. Al hacer esto automáticamente se “envuelve” esa función en una promesa (o sea que esa función pasa a devolver una promesa, a la que podríamos ponerle un await o un .then()).
Podéis ver algunos ejemplos del uso de async / await en la página de MDN.
fetch
Como el código a escribir para hacer una petición Ajax es largo y siempre igual, la API Fetch permite realizar una petición Ajax genérica que directamente devuelve una promesa.
Básicamente lo que hace es encapsular en una función todo el código que se repite siempre en una petición AJAX (crear la petición, hacer el open, el send, escuchar los eventos, …). La función fetch se similar a la función getPosts que hemos creado antes pero genérica para que sirva para cualquier petición pasándole la URL. Lo que internamente hace es algo similar a:
function fetch(url) {
return new Promise((resolve, reject) => {
const peticion = new XMLHttpRequest();
peticion.open('GET', url);
peticion.send();
peticion.addEventListener('load', () => {
resolve(peticion.responseText);
})
peticion.addEventListener('error', () => reject('Network Error'));
})
}
Fijaos en 2 cosas que cambian respecto a nuestra función getPosts():
- fetch devuelve los datos “en crudo” por lo que si la respuesta está en formato JSON habrá con convertirlos. Para ello dispone de un método (
.json()) que hace elJSON.parse. Este método devuelve una nueva promesa a la que nos suscribimos con un nuevo.then. Ejemplo.:fetch('https://jsonplaceholder.typicode.com/posts?userId=' + idUser) .then(response => response.json()) // los datos son una cadena JSON .then(myData => { // ya tenemos los datos en _myData_ como un objeto o array // Aquí procesamos los datos (en nuestro ejemplo los pintaríamos en la tabla) console.log(myData) }) .catch(err => console.error(err));Ese mismo ejemplo usando async/await sería:
try { const response = await fetch('https://jsonplaceholder.typicode.com/posts?userId=' + idUser); const myData = await response.json(); console.log(myData); } catch (err) { console.error(err); } - fetch llama a resolve siempre que el servidor conteste, sin comprobar si la respuesta es de éxito (200, 201, …) o de error (4xx, 5xx). Por tanto siempre se ejecutará el then excepto si se trata de un error de red y el servidor no responde
Propiedades y métodos de la respuesta de fetch
La respuesta devuelta por fetch() tiene las siguientes propiedades y métodos:
- status: el código de estado devuelto por el servidor (200, 404, …)
- statusText: el texto correspondiente a ese código (Ok, Not found, …)
- ok: booleano que vale true si el status está entre 200 y 299 y false en caso contrario
- json(): devuelve una promesa que se resolverá con los datos de la respuesta convertidos a un objeto (les hace un JSON.parse())
- otros métodos para convertir los datos según el formato que tengan: text(), blob(), formData(), … Todos devuelven una promesa con los datos de distintos formatos convertidos.
El ejemplo que hemos visto con las promesas, usando fetch quedaría:
Este ejemplo fallaría si hubiéramos puesto mal la url: contestaría con un 404 pero se ejecutaría el then intentando pintar unos posts que no tenemos.
El ejemplo con async/await y fetch sería:
Gestión de errores con fetch
Según MDN la promesa devuelta por la API fetch sólo es rechazada en el caso de un error de red, es decir, el .catch sólo saltará si no hemos recibido respuesta del servidor; en caso contrario la promesa siempre es resuelta.
Por tanto para saber si se ha resuelto satisfactoriamente o no debemos comprobar la propiedad .ok de la respuesta. El código correcto del ejemplo anterior gestionando los posibles errores del servidor sería:
try {
const response = await fetch('https://jsonplaceholder.typicode.com/posts?userId=' + idUser);
if (!response.ok) {
throw `Error ${response.status} de la BBDD: ${response.statusText}`
}
const myData = await response.json();
console.log(myData);
} catch (err) {
console.error(err);
}
En este caso si la respuesta del servidor no es ok lanzamos un error que es interceptado por nuestro propio catch
Otros métodos de petición con fetch
Los ejemplos anteriores hacen peticiones GET al servidor. Para peticiones que no sean GET la función fetch() admite un segundo parámetro con un objeto con la información a enviar en la petición HTTP. Ej.:
fetch(url, {
method: 'POST', // o 'PUT', 'GET', 'DELETE'
body: JSON.stringify(data), // los datos que enviamos al servidor en el 'send'
headers:{
'Content-Type': 'application/json'
}
}).then(...)
Ejemplo de una petición para añadir datos:
fetch(url, {
method: 'POST',
body: JSON.stringify(data), // los datos que enviamos al servidor en el 'send'
headers:{
'Content-Type': 'application/json'
}
})
.then(response => {
if (!response.ok) {
throw `Error ${response.status} de la BBDD: ${response.statusText}`
}
return response.json()
})
.then(datos => {
alert('Datos recibidos')
console.log(datos)
})
.catch(err => {
alert('Error en la petición HTTP: ' + err.message);
})
Podéis ver mś ejemplos en MDN web docs y otras páginas.
Hacer varias peticiones simultáneamente. Promise.all
En ocasiones necesitamos hacer más de una petición al servidor. Por ejemplo para obtener los productos y sus categorías podríamos hacer:
function getData() {
getTable('/categories')
.then((categories) => categories.forEach((category) => renderCategory(category)))
.catch((error) => renderErrorMessage(error))
getTable('/products')
.then((products) => products.forEach((product) => renderProduct(product)))
.catch((error) => renderErrorMessage(error))
}
function getTable(table) {
return new Promise((resolve, reject) => {
fetch(SERVER + table)
.then(response => {
if (!response.ok) {
throw `Error ${response.status} de la BBDD: ${response.statusText}`
}
return response.json()
})
.then((data) => resolve(data))
.catch((error) => reject(error))
})
}
Pero si para renderizar los productos necesitamos tener las categorías este código no nos lo garantiza ya que el servidor podría devolver antes los productos aunque los pedimos después.
Una solución sería no pedir los productos hasta tener las categorías:
function getData() {
getTable('/categories')
.then((categories) => {
categories.forEach((category) => renderCategory(category))
getTable('/products')
.then((products) => products.forEach((product) => renderProduct(product)))
.catch((error) => renderErrorMessage(error))
})
.catch((error) => renderErrorMessage(error))
}
pero esto hará más lento nuestro código al no hacer las 2 peticiones simultáneamente. La solución es usar el método Promise.all() al que se le pasa un array de promesas a hacer y devuelve una promesa que:
- se resuelve en el momento en que todas las promesas se han resuelto satisfactoriamente o
- se rechaza en el momento en que alguna de las promesas es rechazada
El código anterior de forma correcta sería:
function getData() {
Promise.all([
getTable('/categories')
getTable('/products')
])
.then(([categories, products]) => {
categories.forEach((category) => renderCategory(category))
products.forEach((product) => renderProduct(product))
})
.catch((error) => renderErrorMessage(error))
}
Lo mismo pasa si en vez de promesas usamos async/await. Si hacemos:
async function getTable(table) {
const response = await fetch(SERVER + table)
if (!response.ok) {
throw `Error ${response.status} de la BBDD: ${response.statusText}`
}
const data = await response.json()
return data
}
async function getData() {
const responseCategories = await getTable('/categories');
const responseProducts = await getTable('/products');
categories.forEach((category) => renderCategory(category))
products.forEach((product) => renderProduct(product))
}
tenemos el problema de que no comienza la petición de los productos hasta que se reciben las categorías. La solución con Promise.all() sería:
async function getData() {
const [categories, products] = await Promise.all([
getTable('/categories')
getTable('/products')
])
categories.forEach((category) => renderCategory(category))
products.forEach((product) => renderProduct(product))
}
Organizar bien el código
El fichero .env
En los ejemplos anteriores estamos guardando la URL a la que hacer la petición a la API en una constante a la que estamos llamando SERVER. Esto plantea algunos problemas:
- si tenemos varios ficheros que hacen peticiones a la API deberemos declararla en todos ellos
- si cambia hay que cambiarla en todos los ficheros y en ese caso tenemos que cambiar nuestro código
Para evitarlo podemos almacenar ete tipo de cosas en el fichero .env. Se trata de un fichero donde guardar las configuraciones de la aplicación, como la URL de la API.
Por medio de Vite podemos acceder a todas las variables de .env que comiencen por VITE_ por medio del objeto import.meta.env por lo que en nuestro código en vez de darle el valor a SERVER podríamos haber puesto:
const SERVER = import.meta.env.VITE_URL_API
Y en el fichero .env ponemos
VITE_URL_API=http://localhost:3000
El fichero .env por defecto se sube al repositorio por lo que no debemos poner información sensible (como usuarios o contraseñas). Para ello tenemos un fichero .env.local que no se sube, o bien debemos añadir al .gitignore dicho fichero. Si el fichero con la configuración no lo subimos al repositorio es conveniente tener un fichero .env.exemple, que sí se sube, con valores predeterminados para las distintas variables, que quien quiera desplegar nuestra aplicación deberá cambiar por sus valores adecuados en producción. Además del .env y el .env.local también hay distintos ficheros que son usados en desarrollo (.env.development) y en producción (.env.production) y que pueden tener distintos datos según el entorno en que nos encontramos. Por ejemplo en el de desarrollo el valor de VITE_URL_API podría ser “http://localhost:3000” si usamos json-server mientras que en el de producción tendríamos la ruta del servidor de producción de la API.
Distintas peticiones, distintos ficheros
Las peticiones a la API deberíamos ponerlas en un fichero aparte para tener nuestro código organizado. Y peticiones a diferentes tipos de datos también deberían estar en ficheros diferentes. Por ejemplo si necesitamos obtener datos de posts y de usuarios podríamos crear una carpeta /repositories y dentro los ficheros posts.repository.js y users.repository.js.
Dentro de cada fichero haremos diferentes funciones y métodos para los diferentes tipos de petición, por ejemplo:
const SERVER = import.meta.env.VITE_URL_API
async getAllPosts() {
const response = await fetch(SERVER + '/posts')
if (!response.ok) {
throw `Error ${response.status} de la BBDD: ${response.statusText}`
}
const data = await response.json()
return data
}
async getPostById(idPost) {
const response = await fetch(SERVER + `/posts/${idPost}`)
if (!response.ok) {
throw `Error ${response.status} de la BBDD: ${response.statusText}`
}
const data = await response.json()
return data
}
async insertPost(newPost) {
const response = await fetch(SERVER + '/posts', {
method: 'POST',
body: JSON.stringify(newPost),
headers:{
'Content-Type': 'application/json'
}
})
if (!response.ok) {
throw `Error ${response.status} de la BBDD: ${response.statusText}`
}
const data = await response.json()
return data
}
export {
getAllPosts,
getPostById,
insertPost
}
Y donde necesitemos los datos haremos:
import { getAllPosts } from "../repositories/posts.repositories"
const posts = await getAllPosts()
Usando clases el ejemplo quedaría:
const SERVER = import.meta.env.VITE_URL_API
export default class PostsRepository {
async getAllPosts() {
const response = await fetch(SERVER + '/posts')
if (!response.ok) {
throw `Error ${response.status} de la BBDD: ${response.statusText}`
}
const data = await response.json()
return data
}
async getPostById(idPost) {
const response = await fetch(SERVER + `/posts/${idPost}`)
if (!response.ok) {
throw `Error ${response.status} de la BBDD: ${response.statusText}`
}
const data = await response.json()
return data
}
async insertPost(newPost) {
const response = await fetch(SERVER + '/posts', {
method: 'POST',
body: JSON.stringify(newPost),
headers:{
'Content-Type': 'application/json'
}
})
if (!response.ok) {
throw `Error ${response.status} de la BBDD: ${response.statusText}`
}
const data = await response.json()
return data
}
}
Y donde necesitemos los datos haremos:
import PostsRepository from "../repositories/posts.repositories"
const repository = new PostsRepository()
const posts = await repository.getAllPosts()
Single Page Application
Ajax es la base para construir SPAs que permiten al usuario interactuar con una aplicación web como si se tratara de una aplicación de escritorio (sin “esperas” que dejen la página en blanco o no funcional mientras se recarga desde el servidor).
En una SPA sólo se carga la página de inicio (es la única página que existe) que se va modificando y cambiando sus datos como respuesta a la interacción del usuario. Para obtener los nuevos datos se realizan peticiones al servidor (normalmente Ajax). La respuesta son datos (JSON, XML, …) que se muestran al usuario modificando mediante DOM la página mostrada (o podrían ser trozos de HTML que se cargan en determinadas partes de la página, o …).
Resumen de llamadas asíncronas
Una llamada Ajax es un tipo de llamada asíncrona que podemos hacer en Javascript aunque hay muchas más, como un setTimeout() o las funciones manejadoras de eventos. Como hemos visto, para la gestión de las llamadas asíncronas tenemos varios métodos y los más comunes son:
- funciones callback (no recomendado)
- promesas
- async / await
- librerías, como axios
Cuando se produce una llamada asíncrona el orden de ejecución del código no es el que vemos en el programa ya que el código de respuesta de la llamada no se ejecutará hasta completarse esta. Podemos ver un ejemplo de esto extraído de todoJS usando funciones callback.
Además, si hacemos varias llamadas tampoco sabemos el qué orden se ejecutarán sus respuestas ya que depende de cuándo el servidor finalice cada una, como podemos ver en este otro ejemplo.
Si usamos funciones callback y necesitamos que cada función no se ejecute hasta que haya terminado la anterior debemos llamarla en la respuesta a la función anterior lo que provoca un tipo de código difícil de leer llamado callback hell.
Para evitar esto surgieron las promesas que permiten evitar las funciones callback tan difíciles de leer. Podemos ver el primer ejemplo usando promesas. Y si necesitamos ejecutar secuencialmente las funciones evitaremos la pirámide de llamadas callback como vemos en este ejemplo.
Aún así el código no es muy claro. Para mejorarlo surgió async y await como vemos en este ejemplo. Estas funciones forman parte del estándar ES2017 por lo que no están soportadas por navegadores muy antiguos (aunque siempre podemos transpilar con Babel).
Fuente: todoJs: Controlar la ejecución asíncrona
CORS
Cross-Origin Resource Sharing (CORS) es un mecanismo de seguridad que incluyen los navegadores y que por defecto impiden que se pueden realizar peticiones Ajax desde un navegador a un servidor con un dominio diferente al de la página cargada originalmente.
Si necesitamos hacer este tipo de peticiones necesitamos que el servidor al que hacemos la petición añada en su respuesta la cabecera Access-Control-Allow-Origin donde indiquemos el dominio desde el que se pueden hacer peticiones (o * para permitirlas desde cualquier dominio).
El navegador comprobará las cabeceras de respuesta y si el dominio indicado por ella coincide con el dominio desde el que se hizo la petición, esta se permitirá.
Como en desarrollo normalmente no estamos en el dominio de producción (para el que se permitirán las peticiones) podemos instalar en el navegador la extensión allow CORS que al activarla deshabilita la seguridad CORS en el navegador.
Podéis ampliar la información en numerosaas páginas web como “Entendiendo CORS y aplicando soluciones”.